搜索到
8
篇与
的结果
-
WordPress 博客主题推荐 关于 WordPress 站点的搭建,请参考上篇文章(新手向)手把手教你搭建个人blog ,本文不做赘述。我们直接步入正题:1. Argon 主题作者 : @solstice23发布页面: argon-theme , argon-theme(国内)官方文档: 点击查看示范页面: 官方 Demo, 呐叽的blog网站截图:首页:文章:评论:2. Adams 主题3. 敬请期待……

-
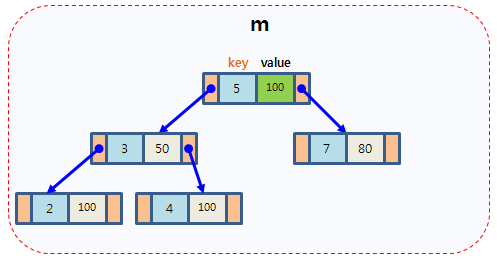
C++ STL容器map用法总结 1,map简介map是STL的一个关联容器,它提供一对一的hash。第一个可以称为关键字(key),每个关键字只能在map中出现一次;第二个可以称为该关键字的值(value);map以模板(泛型)方式实现,可以存储任意类型的数据,包括使用者自定义的数据类型。Map主要用于资料一对一映射(one-to-one)的情況,map內部的实现 自建一棵红黑树 ,这颗树具有对数据 自动排序 的功能,因此map内部所有的数据都是有序的,后边我们会见识到有序的好处。2,map的功能自动建立key - value的对应。key 和 value可以是任意你需要的类型。 3,使用map使用map得包含map类所在的头文件#include <map> //注意,STL头文件没有扩展名.hmap对象是模板类,需要关键字和存储对象两个模板参数:std:map<int, string> personnel;这样就定义了一个用int作为索引,并拥有相关联的指向string的指针.为了使用方便,可以对模板类进行一下类型定义,typedef map<int,CString> UDT_MAP_INT_CSTRING; UDT_MAP_INT_CSTRING enumMap; 4,map的构造函数map共提供了6个构造函数,这块涉及到内存分配器这些东西,略过不表,在下面我们将接触到一些map的构造方法,这里要说下的就是,我们通常用如下方法构造一个map:map<int, string> mapStudent;5,插入元素// 定义一个map对象 map<int, string> mapStudent; // 第一种 用insert函數插入pair mapStudent.insert(pair<int, string>(000, "student_zero")); // 第二种 用insert函数插入value_type数据 mapStudent.insert(map<int, string>::value_type(001, "student_one")); // 第三种 用"array"方式插入 mapStudent[123] = "student_first"; mapStudent[456] = "student_second";以上三种用法,虽然都可以实现数据的插入,但是它们是有区别的,当然了第一种和第二种在效果上是完成一样的,用insert函数插入数据,在数据的 插入上涉及到集合的唯一性这个概念,即当map中有这个关键字时,insert操作是不能在插入数据的,但是用数组方式就不同了,它可以覆盖以前该关键字对 应的值,用程序说明如下:mapStudent.insert(map<int, string>::value_type (001, "student_one")); mapStudent.insert(map<int, string>::value_type (001, "student_two"));上面这两条语句执行后,map中001这个关键字对应的值是“student_one”,第二条语句并没有生效,那么这就涉及到我们怎么知道insert语句是否插入成功的问题了,可以用pair来获得是否插入成功,程序如下// 构造定义,返回一个pair对象 pair<iterator,bool> insert (const value_type& val); pair<map<int, string>::iterator, bool> Insert_Pair; Insert_Pair = mapStudent.insert(map<int, string>::value_type (001, "student_one")); if(!Insert_Pair.second) cout << ""Error insert new element" << endl;我们通过pair的第二个变量来知道是否插入成功,它的第一个变量返回的是一个map的迭代器,如果插入成功的话Insert_Pair.second应该是true的,否则为false。 6, 查找元素当所查找的关键key出现时,它返回数据所在对象的位置,如果沒有,返回iter与end函数的值相同。// find 返回迭代器指向当前查找元素的位置否则返回map::end()位置 iter = mapStudent.find("123"); if(iter != mapStudent.end()) cout<<"Find, the value is"<<iter->second<<endl; else cout<<"Do not Find"<<endl;7, 刪除与清空元素//迭代器刪除 iter = mapStudent.find("123"); mapStudent.erase(iter); //用关键字刪除 int n = mapStudent.erase("123"); //如果刪除了會返回1,否則返回0 //用迭代器范围刪除 : 把整个map清空 mapStudent.erase(mapStudent.begin(), mapStudent.end()); //等同于mapStudent.clear() 8,map的大小在往map里面插入了数据,我们怎么知道当前已经插入了多少数据呢,可以用size函数,用法如下:int nSize = mapStudent.size(); 9,map的基本操作函数: C++ maps是一种关联式容器,包含“关键字/值”对begin() 返回指向map头部的迭代器clear() 删除所有元素-count() 返回指定元素出现的次数empty() 如果map为空则返回trueend() 返回指向map末尾的迭代器equal_range() 返回特殊条目的迭代器对erase() 删除一个元素find() 查找一个元素get_allocator() 返回map的配置器insert() 插入元素key_comp() 返回比较元素key的函数lower_bound() 返回键值>=给定元素的第一个位置max_size() 返回可以容纳的最大元素个数rbegin() 返回一个指向map尾部的逆向迭代器rend() 返回一个指向map头部的逆向迭代器size() 返回map中元素的个数swap() 交换两个mapupper_bound() 返回键值>给定元素的第一个位置value_comp() 返回比较元素value的函数
-
C++ 中 using 的用法 1、概述我们用到的库函数基本上都属于命名空间std的,在程序使用的过程中要显示的将这一点标示出来,如std::cout。这个方法比较烦琐,而我们都知道使用using声明则更方便更安全。这个我们程序员肯定都知道了,今天突发奇想就想对using整理一下。2、命令空间的using声明我们在书写模块功能时,为了防止命名冲突会对模块取命名空间,这样子在使用时就需要指定是哪个命名空间,使用using声明,则后面使用就无须前缀了。例如:using std::cin;//using声明,当我们使用cin时,从命名空间std中获取它 int main() { int i; cin >> i;//正确:cin和std::cin含义相同 cout << i;//错误:没有对应的using声明,必须使用完整的名字 return 0; }需要注意的是每个名字需要独立的using声明。例如:using std::cin;//必须每一个都有独立的using声明 using std::cout; using std::endl;//写在同一行也需要独立声明位于头文件的代码一般来说不应该使用using声明。因为头文件的内容会拷贝到所有引用它的文件中去,如果头文件里有某个using声明,那么每个使用了该头文件的文件就都会有这个声明,有可能产生名字冲突。3、在子类中引用基类成员在子类中对基类成员进行声明,可恢复基类的防控级别。有三点规则:在基类中的private成员,不能在派生类中任何地方用using声明。在基类中的protected成员,可以在派生类中任何地方用using声明。当在public下声明时,在类定义体外部,可以用派生类对象访问该成员,但不能用基类对象访问该成员;当在protected下声明时,该成员可以被继续派生下去;当在private下声明时,对派生类定义体外部来说,该成员是派生类的私有成员。在基类中的public成员,可以在派生类中任何地方用using声明。具体声明后的效果同基类中的protected成员。例如:class Base { protected: void test1() { cout << "test1" << endl; } void test1(int a) {cout << "test2" << endl; } int value = 55; }; class Derived : Base //使用默认继承 { public: //using Base::test1;//using只是声明,不参与形参的指定 //using Base::value; void test2() { cout << "value is " << value << endl; } };我们知道class的默认继承是private,这样子类中是无法访问基类成员的,即test2会编译出错。但是如果我们把上面注释的声明给放开,则没有问题。注意:using::test1只是声明,不需要形参指定,所以test1的两个重载版本在子类中都可使用。 但是在往下派生,则只能使用无参函数,具体什么原因就不知道了…4、使用using起别名相当于传统的typedef起别名。typedef std::vector<int> intvec; using intvec= std::vector<int>;//这两个写法是等价的这个还不是很明显的优势,在来看一个列子:typedef void (*FP) (int, const std::string&);若不是特别熟悉函数指针与typedef,第一眼还是很难指出FP其实是一个别名,代表着的是一个函数指针,而指向的这个函数返回类型是void,接受参数是int, const std::string&。using FP = void (*) (int, const std::string&);这样就很明显了,一看FP就是一个别名。using的写法把别名的名字强制分离到了左边,而把别名指向的放在了右边,比较清晰,可读性比较好。比如:typedef std::string (* fooMemFnPtr) (const std::string&); using fooMemFnPtr = std::string (*) (const std::string&);来看一下模板别名。template <typename T> using Vec = MyVector<T, MyAlloc<T>>; // usage Vec<int> vec;若使用typedeftemplate <typename T> typedef MyVector<T, MyAlloc<T>> Vec; // usage Vec<int> vec;当进行编译的时候,编译器会给出error: a typedef cannot be a template的错误信息。那么,如果我们想要用typedef做到这一点,需要进行包装一层,如:template <typename T> struct Vec { typedef MyVector<T, MyAlloc<T>> type; }; // usage Vec<int>::type vec;正如你所看到的,这样是非常不漂亮的。而更糟糕的是,如果你想要把这样的类型用在模板类或者进行参数传递的时候,你需要使用typename强制指定这样的成员为类型,而不是说这样的::type是一个静态成员亦或者其它情况可以满足这样的语法,如:template <typename T> class Widget { typename Vec<T>::type vec; };然而,如果是使用using语法的模板别名,你则完全避免了因为::type引起的问题,也就完全不需要typename来指定了。template <typename T> class Widget { Vec<T> vec; };一切都会非常的自然,所以于此,模板起别名时推荐using,而非typedef。
-
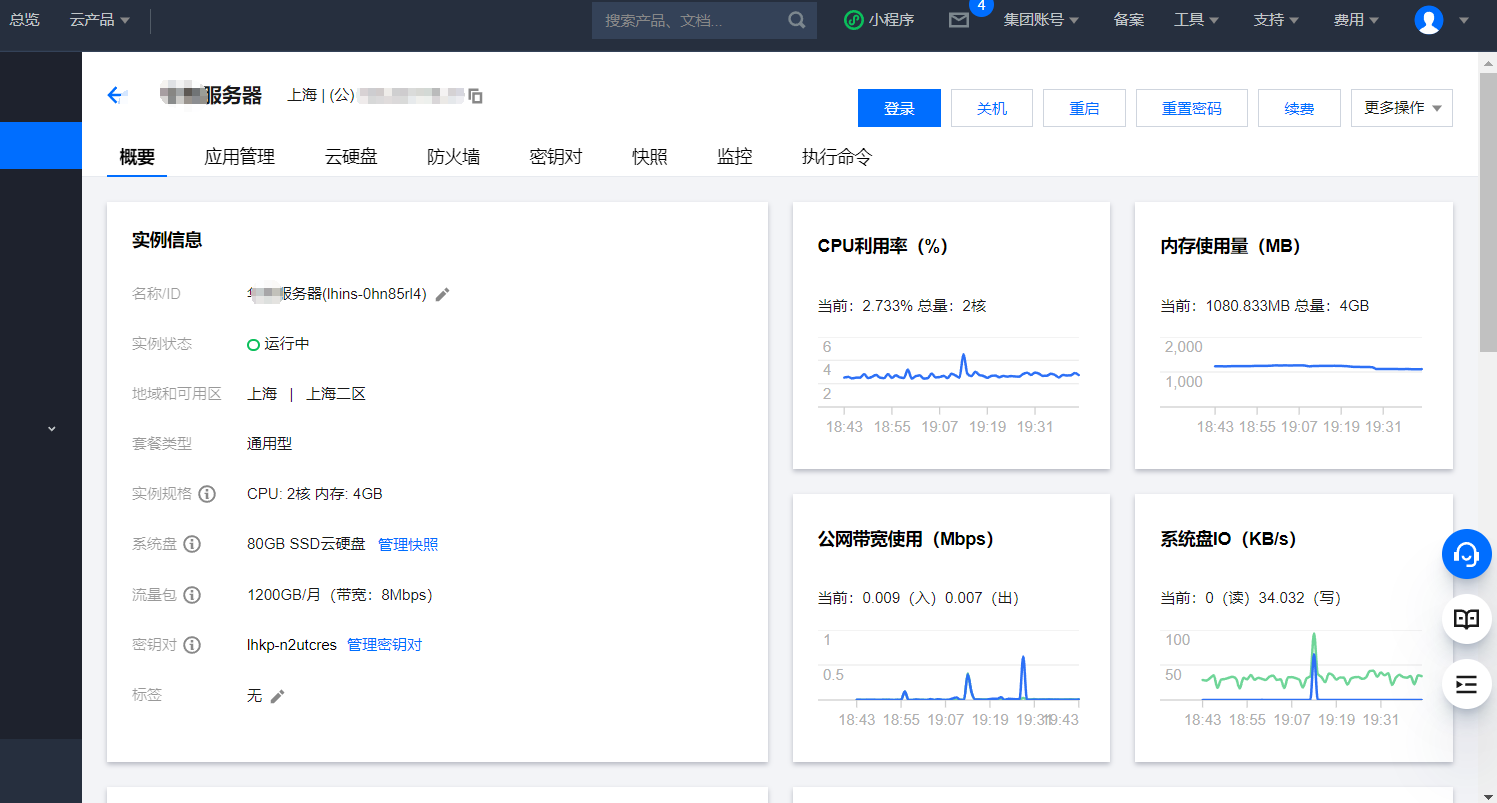
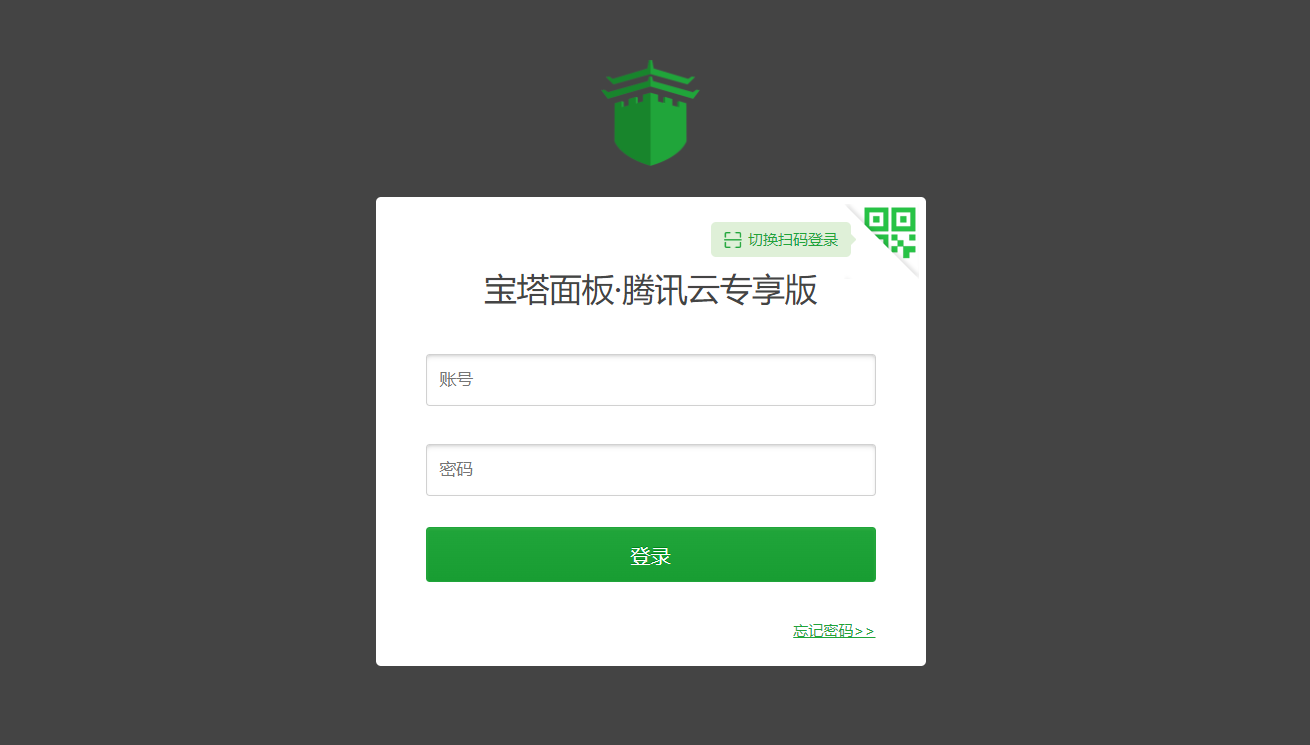
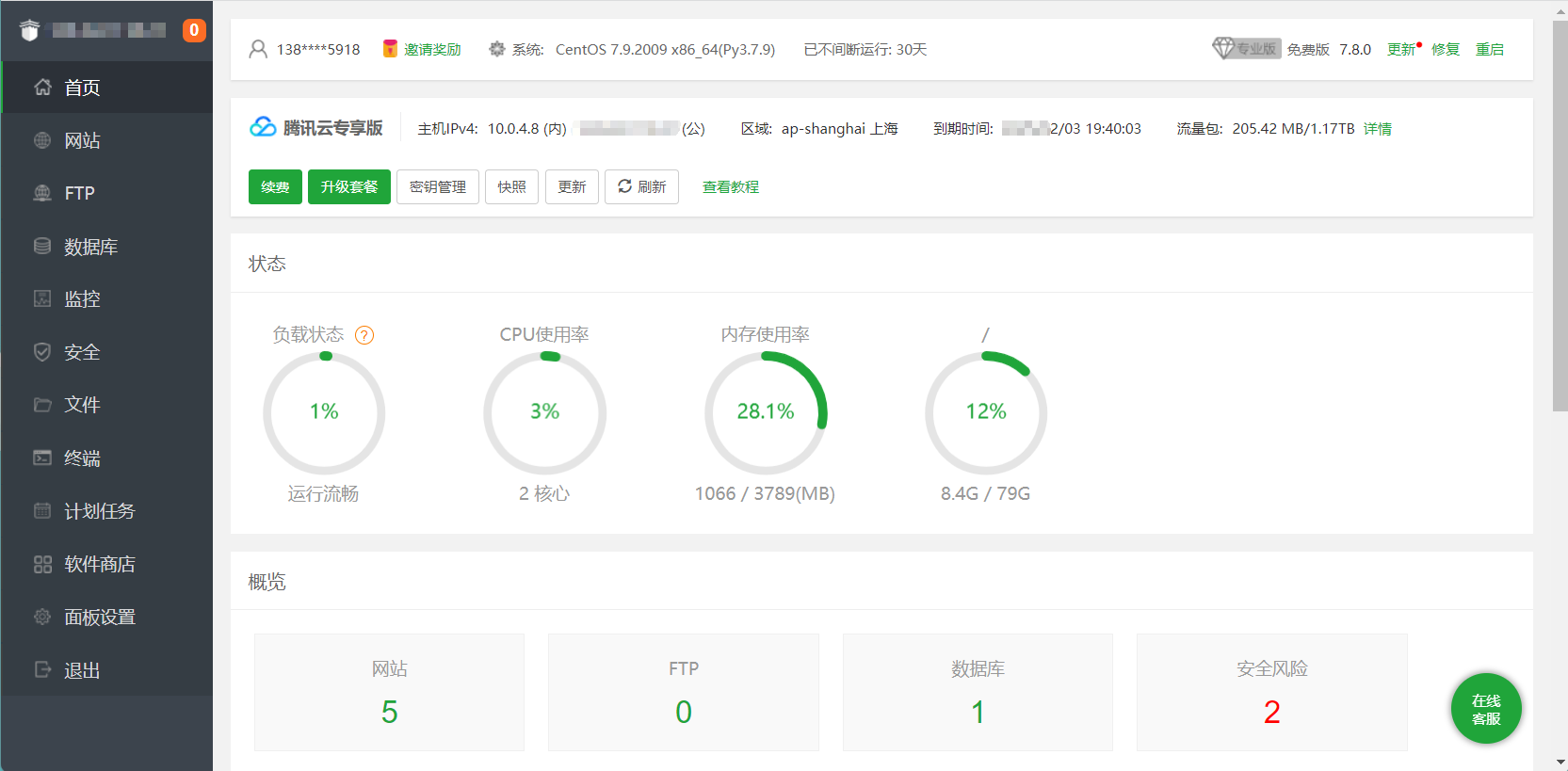
(新手向)手把手教你搭建个人blog 2022年3月8日更新,也就拖更了一个月。本教程面向的对象是 Web 新手,为尽可能扩大受众,语言会略显啰嗦,请谅解。以下为正文:首先,你需要一个域名我们搬出官方的定义:域名(英语:Domain Name),又称网域,是由一串用点分隔的名字组成的Internet上某一台计算机或计算机组的名称,用于在数据传输时对计算机的定位标识(有时也指地理位置)。很拗口,没关系,通俗的说域名是IP地址的一层面具,用来帮助记忆并提升服务器安全性,比如本站的域名 zzaiyan.com。获取域名最直接的方法是向域名服务商(阿里云,腾讯云等)购买,读者可自行了解。其次,你需要一台云服务器我们首选的是云服务器(Elastic Compute Service),即ECS,作为通用服务器,能满足各种服务应用。对于以学习为目的建站的学生,这里推荐ECS的平替,如VPS,Lighthouse(即轻量应用服务器),它们在价格上有着巨大的优势,且性能足以满足大多数非商业需求。至于服务器的配置,我建议选购1核2G以上的服务器,能在保证流畅运行多个网站(低访问量)的同时,搭建一些其他应用,如私有云盘,邮箱服务,线上IDE等。关于云服务器系统选择购买服务器后,运营商会询问我们需要安装的系统镜像。为了节约系统资源,并提高一定的兼容性,这里推荐选择一些Linux发行版,如CentOS,Ubuntu,后文我将以 宝塔面板(基于CentOS 7.9)为例,演示相关程序的部署。大部分平台选购服务器时会提供初始系统,为节省安装时间,避免掉坑,建议选择已配置好宝塔面板的 Ubuntu 或 CentOS;关于如何在现有 Linux系统安装宝塔面板,此处不进行阐述,请自行查找现有教程。现在我们来熟悉服务器的管理面板服务器部署完毕后,我们可以从运营商(如腾讯云)的控制台查找服务器的公网IP地址。IP地址相当于服务器的门牌号,安全起见请勿随意暴露。登录服务器供应商网站,进入控制台,选择我们所购买的服务器,我们可以看到服务器的管理面板。下图为腾讯云服务器的概览页面:在服务器的管理面板,我们需要找到宝塔面板的默认登录账号密码并记录,以便后续操作。打开浏览器,输入 IP地址:8888/login 按回车,输入刚才记录的账号密码,我们便进入了宝塔面板的后台。下图为登录后的宝塔面板:宝塔面板功能众多,其中最为常用的便是管理网站,本文将对此进行重点阐述(也就是说别的功能都不讲)。让我们建立一个属于自己的站点在宝塔面板主页,我们点击左侧栏,选择“网站”页面,点击“添加站点”,在弹出的对话框中输入相关信息。网站域名填写我们此前购买的域名(如果没买可以先填公网IP),备注名随意,然后无脑下一步即可。这里我们在网站列表中找到我们刚创建的网站,点击右侧的设置按钮,进入“伪静态”选项卡,选择“wordpress”规则,然后保存。(该步骤的作用暂时不做讲解,界面如下图)我们还需要设置域名解析至此,我们建立了一个专属于自己的网站,但我们还无法对其进行访问。这时我们需要设置域名解析,通俗地说就是使你的域名指向服务器的地址,让浏览器正确识别这个名字所代表的服务器。我们登录购买域名的服务商平台(我使用的是阿里云,即万网),进入控制台管理域名,选择云解析DNS,依次点击新手引导、网站解析,并输入服务器公网IP地址保存即可。此处我示范的是阿里云域名,不同的服务商管理界面具体操作大同小异,相信读者们能够正确设置解析。这时候,我们使用任何一台联网的Web设备,输入该域名即可访问到我们的页面,效果如下:当我们看到这个界面,说明目前为止我们的操作都正确无误,服务器和DNS都在正常工作。接下来,我们需要部署网站程序此时我们虽然拥有了一个可以正常访问的网站,但它目前只有相当朴素的几句提示词,没有任何实质内容,所以我们需要部署网站程序来实现美观的界面和各式各样的功能。作为基础薄弱的学生,让我们从零开始写出一个博客网站无疑是困难的(其实是根本不会),所幸有众多前辈开发了大量成熟的网站框架,或称之为CMS(内容管理系统),仅博客类就有 WordPress、Z-Blog、Typecho 等常用CMS。作为最为大众,也是二次开发最为成熟的CMS,WordPress无疑是最适合新手使用的,接下来,我以此为例,演示网站代码的部署。首先我们访问 WordPress 的官网通过搜索引擎检索 WordPress 、直接访问其 官方网站 ,或直接 点我下载 ,我们可以轻松得到最新版WP的安装包(下载的zip文件约20MB大小)。其实我们也可以跳过下载安装包的步骤,直接调用服务器远程下载,下文我们将介绍到。让我们回到宝塔面板登录宝塔面板,通过左侧栏进入“文件”页面,进入我们之前添加站点时创建的目录,如下图:我们点击左上角的上传按钮,选择我们此前下载的安装包文件,或点击远程下载按钮,输入文件 URL https://cn.wordpress.org/latest-zh_CN.zip ,点击确认后稍作等待,zip 文件将被下载到服务器中。下载完成后,我们在文件目录中右键压缩包,解压文件到当前目录,随后目录中会新增 wordpress 文件夹,此时我们删除其他文件,如下图:然后我们进入 wordpress 文件夹,全选文件,将其剪切到上一级目录,以便后续的安装。进行上述操作后,我们的文件目录如下:至此我们已经安装好网站程序,在执行安装程序前,我们还需要建立一个数据库。为网站建立一个数据库回到宝塔面板首页,点击左侧栏的“数据库”,在数据库界面点击添加数据库,设置数据库名,用户名和密码(宝塔面板会保存下来,随时可以查看),点击确认即可成功创建。该步配图略。现在,我们执行网站的安装程序打开浏览器,输入我们的域名(也可能是 IP 地址),我们便能看到 WordPress 的安装程序,界面如下:在安装程序中,输入我们刚才建立的数据库的信息,然后再对网站的相关信息和管理员账户进行设置,点击安装,随后我们会进入 WordPress 的后台界面,输入管理员账号密码登录后,我们便来到了 WordPress 的仪表盘,如下图所示:如果进行到现在一切顺利,那么恭喜你,我们已经成功的建立了一个 WordPress 站点,我们将光标移至仪表盘左上角,点击查看站点即可访问我们的网站。笔者安装时,WordPress 的默认主题如下:若想使网站更美观,可以在仪表盘中修改网站主题,建议筛选 Blog 相关的主题,以适应我们的写作需要。打个广告:下一篇博客将会推荐 WordPress 网站主题,并提供相关示范页面,敬请期待……(文章已推出,链接在文末)为你的网站添加文章作为个人博客,最最重要的便是内容。我们现在有了网站,但除了《你好,世界》外,还没有任何文章,下面我们回到 WordPress 的仪表盘,为网站添加文章并进行写作。在浏览器中输入 http://你的域名/wp-admin/ 即可登录进入仪表盘,点击左侧栏中的“文章” “写文章” 便能进入写作界面。WordPress 默认的写作以板块为单位,能方便地插入图片、链接和引用等内容,我们随便撰写了一篇文章,样式如下:完成写作后点击发布,我们的文章便被保存于后端,并出现在网站首页,随时随地可以被访问。打开我们的网站首页,可以清晰地看到我们刚刚发表的文章,首页展示的内容也可以在仪表盘中自主修改。(本文完结)引申阅读: WordPress 博客主题推荐
-
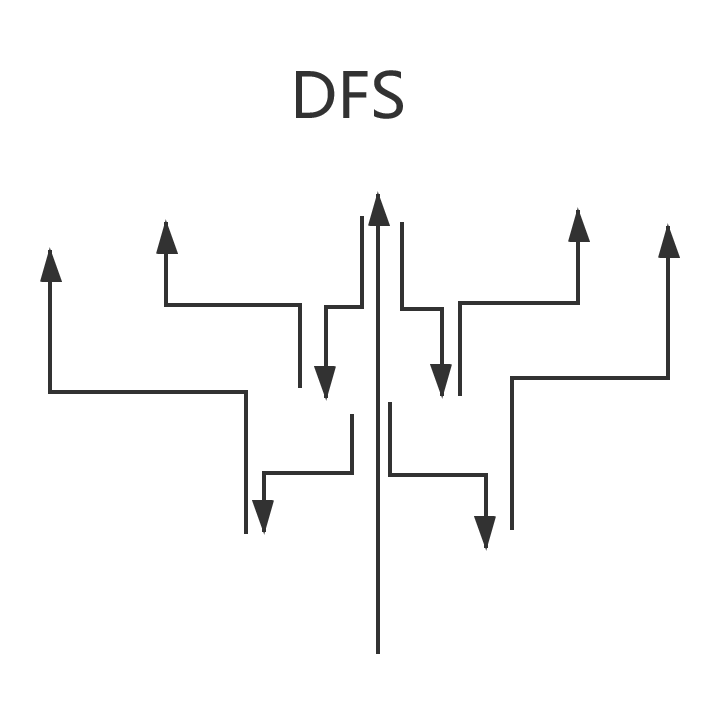
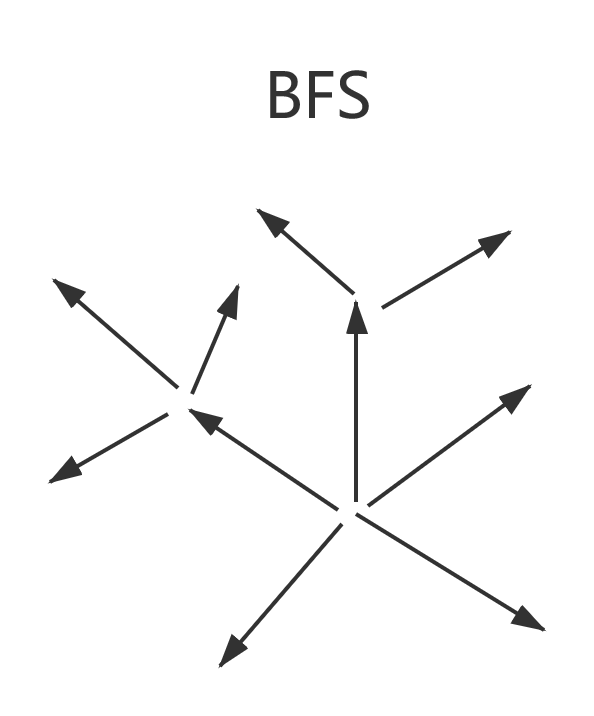
一文弄懂搜索算法中的DFS和BFS 0x01.前序有一位小伙伴问我,迷宫问题怎么解决,我说DFS或者BFS,然后,TA 说,哦哦,这我知道,就是图里面的算法嘛,但,这是个迷宫,难道我要把这个二维矩阵变成图嘛?我:当场去世。。。 于是我开启了我的长篇大论。。。希望大家有所收获。0x02.DFS和BFS简要介绍首先,回答一下那位小伙伴的问题,这个算法确实属于图里面的算法,但并不是说是专门针对图的算法,它在算法领域应用非常广泛,可以说是一种不可缺少的思想。官方说明:DFS:深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。BFS:宽度优先搜索算法(又称广度优先搜索)是最简便的图的搜索算法之一,这一算法也是很多重要的图的算法的原型。Dijkstra单源最短路径算法和Prim最小生成树算法都采用了和宽度优先搜索类似的思想。其别名又叫BFS,属于一种盲目搜寻法,目的是系统地展开并检查图中的所有节点,以找寻结果。换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为止。简要理解:说实话,我第一次看没看懂,确实比较官方,我们可以用我们的思维去简单的理解一下:DFS:深度优先搜索,是一种搜索算法,讲究搜索的深度,所以叫深度优先算法。又叫回溯算法。这个算法的核心就是不断的往更深的地方搜索,如果更深的地方搜索失败了,就返回来搜,是一个回溯的过程。BFS:广度优先搜素,也是一种搜索算法,讲究搜索的广度,所以叫广度优先算法。这个算法的核心就是,先把周围的找完,再去找更深的地方。- 通俗易懂的说法:DFS就是一条路走到底,发现没路了,返回来,走另一条路。BFS就是每条路都走一点,走一点点后就走另一条路了。不如看张图,看图吧: 如果你还对这两种方式不理解,你可以看一下。0x03.DFS和BFS的实现方式这两种算法的不同主要在于优先级的不同,所以实现方式是很相似的。这两种算法都可以使用的递归的方式,其中DFS还可以用栈来实现,BFS还可以用队列实现。具体的实现,可以参考 :DFS和BFS用递归实现的思路:根据各自传参的优先级的顺序,不断的调用自身。- 一般情况下,用递归实现BFS比较为难,所以常用队列实现。DFS用栈实现的思路:每遇到一个元素,就把这个元素的所有邻接元素入栈,当栈不为空的时候,不断的从栈顶拿出元素进行操作,直到栈为空。BFS用队列实现的思路:每遇到一个元素,就把这个元素的所有邻接元素放入队列,当队列不为空的时候,不断从队首拿出元素进行操作,直到队列为空。特别的:在非递归的实现中,你只需要把DFS的栈全部改为队列,它就变成BFS了哦~0x04.DFS和BFS的应用区别其实,大部分问题都是既可以用BFS,也可以用DFS的,但是这两种算法面对不同的问题,解决效率并不一样。BFS类似于水波纹的扩散,在求解一些最短路径,最优值问题的时候效率很高。BFS为了遍历,需要保存所有的状态,对空间来说是一个巨大的消耗。(因为通常是无法递归实现的)DFS主要应用于回溯的搜索问题中,比如迷宫问题,岛屿问题。DFS能够做到使用一个状态变量去搜索所有的状态空间,这对空间的消耗来说,是非常节约空间的(通常使用递归实现)。0x05.如何根据问题选择实现方式我的观点就是:无特殊情况,DFS就用递归实现,BFS就用队列实现。我们看一下两种实现方式对处理问题带来的不同:使用递归的方式对于恢复状态非常方便,因为大部分问题在回溯后都需要恢复相应的状态使用非递归方式对于一些求值问题来说,比较容易理解的产生原理。递归可能消耗时间会多一些。使用栈和队列可能空间消耗会非常大。非递归实现的解决问题方式,一目了然,比较容易看懂。递归解决,如果你对递归的调用过程还不是非常清晰的时候,可能就比较难理解。DFS无特殊情况就使用递归的原因是,递归更能体现这种回溯的思路。BFS无特殊情况就使用对垒实现的原因是,一般递归实现会比较难。0x06.如何使用这两种算法去解决相应的问题第一步,确定什么问题可以用这两种算法解决:(可别说只针对图了啊)凡是在一个二维矩阵中,找路径,找方法数,搜索东西,想都不要想,一般都可以用上。- 去遍历图肯定是可以的看到有关找方法的问题,可以尝试使用。- 凡是包含搜索思想的,都可以使用。第二步,确定使用的算法和实现形式,具体看上文。第三步,根据题目的需求,确定搜索失败后是否需要还原状态,求值问题是否需要更新值。第四步,设计针对性的算法。注意事项:关于求种数问题,一定要明白,每一步递归返回值的含义。- 求最短路径问题,搜索失败后,一定要还原状态,比如某些标志遍历,或者矩阵里的坐标之类的。调试小技巧:通过输出关键操作的值,来确定程序执行的顺序,确定出错原因。0x07.常用的优化算法的思路我们设计算法,不是为了单纯AC问题,而是,追求极致,比如,这个: 优化时间的思路:过滤没有必要的递归。- 合适的使用相应的数据结构。- 传参的时候传实参(指针或者引用),如果传形参会造成反复拷贝参数,如果参数过大的话,会超出时间限制。优化空间的思路:在需要恢复状态的时候,可以采用沉岛思想,不过需要题目适用。- 沉岛思想的关键是把已经访问过的值,变成一些完全不可能的值,避免重复访问,也可以根据是否需要恢复状态,考虑是否可以直接删去。0x07.谈谈它们的鼻祖这两种算法的鼻祖就是搜索算法,搜索算法的核心就是遍历到所有可能的情况,所以,常见的暴力枚举也是搜索算法的一种,所以我们在采用这两种算法的时候,思路就已经是在遍历所有可能的情况了,但是在这其中,可以借助贪心的思维去优化,做到不必要遍历每种情况。0x08.如何快速提升使用它们的能力算法,还是要使用,所有,多练习经典的题目吧!!! 下面是一些比较经典的题目,你也可以尝试去做N皇后问题,迷宫问题。最后,多练多收获!!!